
快速排序可以说是冒泡排序的升级版
1.基本思想:
采用的是分治策略(一般与递归(套娃)结合使用),以减少排序过程中的比较次数。
任取待排序记录序列中的某个记录(例如取第一个记录)作为基准(枢),按照该记录的关键字大小,将整个记录序列划分为左右两个子序列:
左侧子序列中所有记录的关键字都小于或等于基准记录的关键字
右侧子序列中所有记录的关键字都大于基准记录的关键字
图示: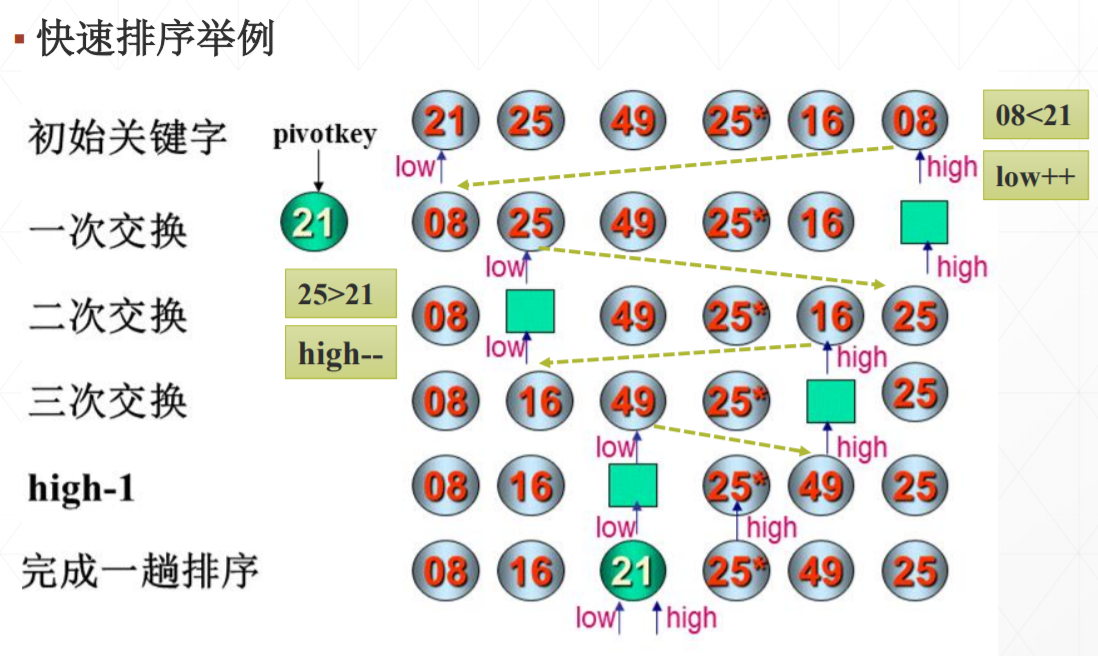

2.算法:
1、取序列第一个记录为枢轴记录,其关键字为Pivotkey;指针low指向序列第一个记录位置(low=1),指针high指向序列最后一个记录位置(High=SeqList. Len)
2、从high指向的记录开始,向前找到第一个关键字的值小于Pivotkey的记录,将其放到low指向的位置,low++
3、从low指向的记录开始,向后找到第一个关键字的值大于Pivotkey的记录,将其放到high指向的位置,high–
4、重复2、3 ,直到low == high ,将枢轴记录放在low(high)指向的位置
3.算法性能:
平均时间复杂度为O(nlog2n),最坏复杂度是O(n2),就平均计算时间而言,快速排序是所有内排序方法中最好的一个,但是快速排序是一种不稳定的排序方法。
4.C++程序实现:
1 | #include <iostream> |